인프런 - 자바 ORM 표준 JPA 프로그래밍 - 기본편 강의노트
영속성 컨텍스트의 이점
1. 1차 캐시
- 저장
Entity를 영속성 컨텍스트에 저장할 때, EntityManager가 Entity를 영속성 컨텍스트의 1차 캐시에 저장한다.
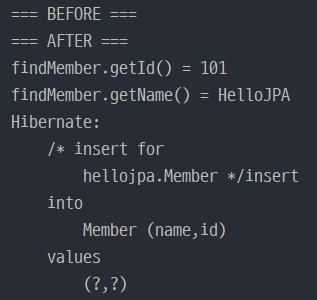
em.persist(member)이후 find를 넣었는데 쿼리는 commit할 때 나간다.
DB단에서 조회해오지 않고, 1차 캐시에서 조회해 오기 때문.
// 비영속
Member member = new Member();
member.setId(101L);
member.setName("HelloJPA");
//영속
System.out.println("=== BEFORE ===");
em.persist(member);
System.out.println("=== AFTER ===");
Member findMember = em.find(Member.class, 101L); // 쿼리를 보내지 않는다.
System.out.println("findMember.getId() = " + findMember.getId());
System.out.println("findMember.getName() = " + findMember.getName());
tx.commit(); // 이 때 저장하는 쿼리를 보낸다.em.persist(member)이후 find를 넣었는데 쿼리는 commit할 때 나간다.
DB단에서 조회해오지 않고, 1차 캐시에서 조회해 오기 때문.
- 조회
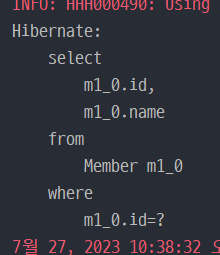
어떤 Entity를 조회하려고 할 때, EntityManager는 영속성 컨텍스트의 1차 캐시를 먼저 조회한 후, 1차 캐시에 있으면 Entity를 리턴해주고, 없으면 DB에서 조회하여 1차 캐시에 저장 후, 리턴해준다.
1차 캐시에서 저장을 해주긴 하지만, 고객의 요청이 끝나면 영속성 컨텍스트는 없어지므로 1차 캐시도 같이 없어진다. 한 로직 안에서는 이득을 볼 수 있지만, 모든 고객의 요청을 생각하면 그렇게까지 이득은 아니다. 비지니스로직이 복잡해지면 도움이 될 수도 있다.
Member findMember1 = em.find(Member.class, 101L);
Member findMember2 = em.find(Member.class, 101L);
tx.commit();똑같은 ID로 같은 Entity를 두 번 조회했을 때 쿼리는 단 한 번 날라간다. 한 번 쿼리를 날려 DB에서 조회한 Entity는 1차 캐시에 저장해 놓기 때문이다.
2. 동일성(identity) 보장
1차 캐시로 반복 가능한 읽기(REPEATABLE READ) 등급의 트랜잭션 격리 수준을 데이터베이스가 아닌 애플리케이션 차원에서 제공
마치 자바 컬렉션에서 똑같은 참조가 있는 객체를 꺼내면 똑같은 것처럼 해준다. 1차 캐시가 있기 때문에 가능. 같은 트랜잭션 안에서!!
Member findMember1 = em.find(Member.class, 101L);
Member findMember2 = em.find(Member.class, 101L);
System.out.println(findMember1 == findMember2); // true3. 트랜잭션을 지원하는 쓰기 지연(transacional write-behind)
트랜잭션을 commit하기 전까지 쿼리문을 데이터베이스에 보내지 않는다. (예외도 있긴 있다.)
영속성 컨텍스트 안에서는 쓰기 지연 SQL 저장소라는 것이 있는데, em.persist(memberA); 라는 명령이 들어오면 EntityManager는 memberA 객체를 1차 캐시에 저장하고, 객체를 분석하여 그에 맞는 쿼리를 쓰기 지연 SQL 저장소에 저장해 놓는다. 이러한 과정을 거쳐 SQL 저장소에 모아둔 쿼리를 트랜잭션이 커밋되면 한꺼번에 DB로 보낸다.
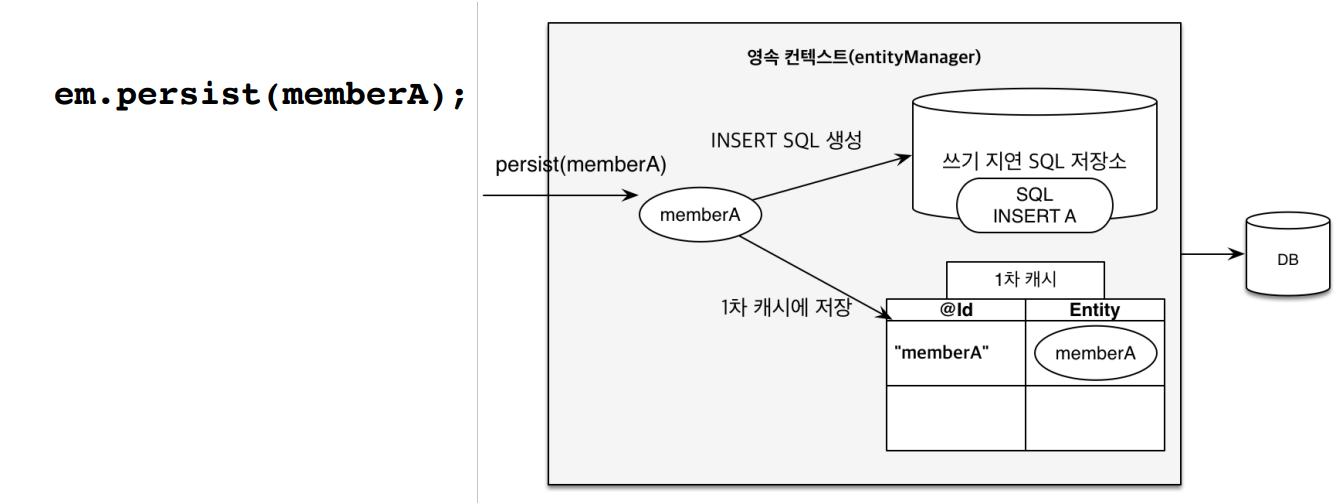
+) 영속성 컨텍스트에 저장할 때마다 DB에 쿼리를 날린다면 최적화 할 수 있는 여지가 없다...! 기능을 잘 활용하면 실행 속도를 향상 시킬 수 있다.
+) 하이버네이트 배치
배치 작업은 대량의 작업을 한번에 처리하는 경우를 말한다. 이와 유사하게 하이버네이트 배치는 JDBC에서 제공하는 배치기능을 활용한다.
다음 코드를 persistence.xml에 추가했다고 하면,
<property name="hibernate.jdbc.batch_size" value="10"/>하이버네이트 배치기능을 적용하게 되면 설정한 배치 갯수. 여기서는 10에 도달할 때까지 PreparedStatement.addBatch()를 호출하여 실행할 쿼리를 추가하고, 설정한 배치 갯수에 도달하게 되면 PreparedStatement.executeBatch()를 호출한다.
DB 드라이버에서는 executeBatch()가 호출되면 addBatch()를 통해 추가된 쿼리를 재조합하여 DB로 한 번에 전송한다.
여러 개의 쿼리를 한 번에 모아서 처리하기 때문에 단건식 쿼리를 수행할 때에 비해 DB와 통신하는 횟수도 줄어들고, DB에서도 락을 잡는 횟수가 줄어들어 실행 속도가 향상되게 된다.
4. 변경 감지(Dirty Checking)
update()를 하지 않아도 조회한 데이터에서 변경된 필드를 감지하여 알아서 update()해준다. 다른 말로 하면 값이 바뀌면 무조건 update 쿼리가 날아간다.

Member member = em.find(Member.class, 150L);
member.setName("ZZZZZ");
System.out.println("====================");
tx.commit();처음에 find 쿼리문이 날아가고 === 이후 commit을 해주니까 알아서 update쿼리문이 날아가는 것을 볼 수 있다.


내부 동작
commit → flush() → 엔티티와 스냅샷 비교 → 다른 점이 있다? → UPDATE SQL 생성 → DB에 반영
스냅샷? 영속성 컨텍스트의 1차 캐시에다가 Entity의 값을 읽어온 최초 시점에 스냅샷을 떠둔다. 첫 값 저장해놓는 곳.

참고 링크
MySQL 환경의 스프링부트에 하이버네이트 배치 설정 해보기 | 우아한형제들 기술블로그
{{item.name}} 안녕하세요. 배민상품시스템팀 권순규 입니다. 저희팀에서 하이버네이트 배치 설정을 통해 대량 insert/update 시의 속도개선을 경험하여 공유드리고자 합니다. 전체 예제 파일은 github
techblog.woowahan.com
'STUDY > JPA' 카테고리의 다른 글
| [3-4] 준영속 상태 (0) | 2023.07.06 |
|---|---|
| [3-3] 플러시 (0) | 2023.07.05 |
| [3-1] 영속성 컨텍스트란? (0) | 2023.07.03 |
| [2-1] JPA 시작하기 (0) | 2023.06.30 |
| [1-2] JPA 소개 (0) | 2023.06.29 |